With two possible experimental trials
(signal present or absent) and two possible participant responses ("yes"
it is present or "no" it isn't there) there are four possible outcomes
to each of many trials.
|
Signal
|
|
|
|
|
|
|
|
Present
|
|
|
|
Absent
|
|
|
Calculating d' From a Single Outcome matrix
Data required for each point on an isosensitivity (ROC) curve requires hundreds of trials (to get accurate probabilities for Hits and False Alarms). With a few assumptions, d' can be calculated from a single outcome matrix using Signal Detection theory.
This method assumes that:
1. Noise is normally
distributed. Presenting a signal on top of that noise, will therefore shift
the amount of sensory activity to the right (higher), by an amount equal
to that sensory systems sensitivity to that signal. The difference between
the mean amount of sensory activity generated by the noise alone trials
and the signal+noise trials will equal sensitivity (d') measured
in z-score (standard deviation) units.
2. Participants adopt
a criterion (b)
for dealing with those values of sensory activity that could result from
either noise alone or signal plus noise (the area where the noise and signal+noise
distributions overlap). If the amount of sensory activity exceeds that
amount, the participant will say the detected the signal, any amount less
than that and they will say they did not detect the signal.
With these assumptions, the four cells of an outcome matrix can be represented as areas under the two normal distributions (for sensory activity experienced on noise alone trials and signal+noise trials).
d' = ZFA - ZHit
Tables for the z-score distribution or percent area under the normal curve typically present the z-score distances between the mean and the Criterion value (b). If you are using such a table, ZFA can be found by looking up the z-score associated with (50 - False Alarm %). If this number is positive, then the z-score to be put into the above formula will also be positive, if it is negative, the z-score value for the formula will also be negative. It is essential that the proper signs be used. A good way of checking would be to draw the distributions and the criterion and see the relationship between d' and the two z-scores. Similarly, to find ZHit, look up (50 - Hit %), again, the resulting sign will be the same as is used for the z-score in the formula.
E.g.,
|
Signal
|
|
|
|
|
|
|
|
Present
|
|
|
|
Absent
|
|
|
looking up the z-score associated with 50-20= 30% of the area under the normal curve, it is .842; for 50-60= -10% it is .253. Since 50 - 60 is a negative, -.253 is put into the formula to get:
d' =.842-(-.253)
= .842+.253= 1.095
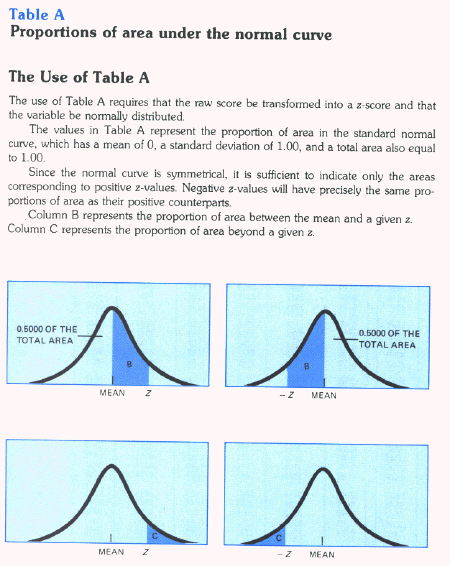
Here are some tables of the normal distribution z scores that show both area
between z and the mean, and area beyond z.
Click here for the use of the table
Click here for:
z = 0.00 to 1.64
area between z and mean = .0000 to .4495
area beyond z = .5000 to .0505
Click here for:
z = 1.65 to 4.00
area between z and mean = .4505 to .49997
area beyond z = .0495 to .00003
Another way to compute d':
Because P(h) and P(fa) correspond to areas under the two distributions, these values can be used to compute d' for a set of data. To compute d', we have to discover how many normal standard deviates lie between the mean of the noise distribution (Xn) and the mean of the signal distribution (Xs). This calculation is the same as computing the z-score associated with the criterion (Xc) if that criterion is considered as part of the noise distribution. Let us assume that P(h)=.75 and P(fa)=.10.
We can determine the z-score value of Xc on the noise distribution because we know what proportion (the false alarm rate) of all the noise trials lie to the right of Xc. We know this because we know the number of noise trials we presented to the subjects, and we also know how many false alarms they made! P(fa)=number of false alarms / number of noise trials. Likewise, the hit rate is P(h)=number of hits / number of signal trials.
Using a table of the normal distribution, we find that a z-score of 1.28 leaves 0.10 in the area under the tail of the noise distribution to the right of it. Next we compute the z-score distance between Xc and Xs (mean of signal distribution). From P(h)=.75 we know that 75% of the signal distribution lies to the right of Xc, which means that Xc is approximately .68 standard deviations below Xs. To compute d' we simply add the two standard deviation scores and obtain d' = 1.96.
In an excel spreadsheet, you can find the z score associated with a
probability using the formula NORMSINV(prob), where prob is P(h) or P(fa). It
gives you the area under the curve of the normal distribution,
and the calculation of d' should be:
d' = NORMSINV( P(h) ) - NORMSINV( P(fa) )
For example, say P(h) = .7 and P(fa) = .1
NORMSINV( .7 ) = 0.52
NORMSINV( .1 ) = -1.28
d' = 0.52 - (-1.28) = 1.81
Try the numbers in the very first example above:
d' = NORMSINV( .6 ) - NORMSINV( .2 )
d' = 0.253 - (-0.842) = 1.095
{kind=link}
{kind=link}
{kind=link}